Language: English
Building a Scalable Backend for an LLM Chatbot During a Two-Week Internship at GMO Internet Group
During a two-week internship in GMO Internet Group's ML/WEB course, I joined a five-person team building an MVP and took charge of the backend for an LLM chatbot. This is a retrospective on the requirements, technology choices, design decisions, failures, and lessons learned.
This article is about something that happened a while ago already, but I joined GMO Internet Group’s two-week ML/WEB internship program.
The theme was very hands-on: in two weeks, a team of five of us built an MVP for an existing product called Tenbin AI. I was responsible for the API and backend for the LLM chatbot. In short projects, it is tempting to focus on getting something working as fast as possible. What I felt strongly this time, though, was that short timelines make it even more important to optimize for “working correctly” rather than just “working.”
What Is Tenbin AI?
Tenbin AI is a GMO product that sends the same prompt to multiple generative AI models such as ChatGPT, Claude, and Gemini at the same time, then lets you compare up to six responses on a single screen. Its core value is that you can see each model’s strengths and weaknesses side by side and choose the one that fits your purpose. Because it provides a unified UI for multiple models, it is useful for things like research, drafting text, brainstorming, and prompt improvement.
What I Built
The backend I worked on had the following requirements.
- Send requests to GPT and Gemini at the same time and display their responses side by side for comparison
- Create, retrieve, and delete chat sessions
- Persist message history
- Measure and aggregate token usage
- Allow users to vote on LLM responses
The processing flow itself was fairly simple. Once a user submitted a message, we first saved it, then fired asynchronous requests to multiple LLMs in parallel. The backend returned 202 Accepted immediately. After the LLM responses came back, we saved them, published an event, and let the frontend re-fetch the list when it received that event.
That structure let us keep the backend stateless while still delivering an experience that felt close to real time.
API Procedures I Implemented
These are the procedures I implemented.
v1.health.checkHealth check for the backendv1.catalog.listLlmsReturns the list of available LLM modelsv1.chatSession.listGets the list of chat sessions owned by the userv1.chatSession.getRetrieves session details, including metadata and statev1.chatSession.createCreates a new sessionv1.chatSession.updateTitleUpdates a session titlev1.chatSession.deleteDeletes a sessionv1.chatMessage.listRetrieves the messages associated with a sessionv1.chatMessage.sendThe core API in this project. It sends requests to GPT and Gemini in parallel.v1.chatMessage.voteLets users vote on LLM responses. We supported eight evaluation items, including something like a “like,” so we could collect feedback for model comparison.
As I mentioned at the beginning, there were five of us on the team, roughly split into one person on infrastructure, two on the backend, and two on the frontend. The other backend engineer handled a large part of the database design, so I will only touch on that briefly here. Also, procedures outside the chatMessage area were mostly straightforward CRUD around the database, so this post focuses mainly on the chatMessage procedures.
About the Database
We split the database by use case between Aurora MySQL and DynamoDB. Data that needed listing or aggregation went into Aurora, while time-series message details went into DynamoDB.
On the Aurora side, we managed session lists, titles, user ownership, cumulative token counts per model, and estimated costs. Vote data and its aggregations also lived there. In other words, the relational database handled data that benefited from sorting, aggregation, and joins across related entities.
On the DynamoDB side, we stored the user’s messages and each model’s response body, token count, cost, and latency as detailed records. Because one user input fanned out into multiple model responses, we designed the data so it would be easy to retrieve chronologically at the session level. Put simply: message bodies in DynamoDB, lists and aggregations in Aurora.
Processing Flow From Sending a Chat to Rendering It
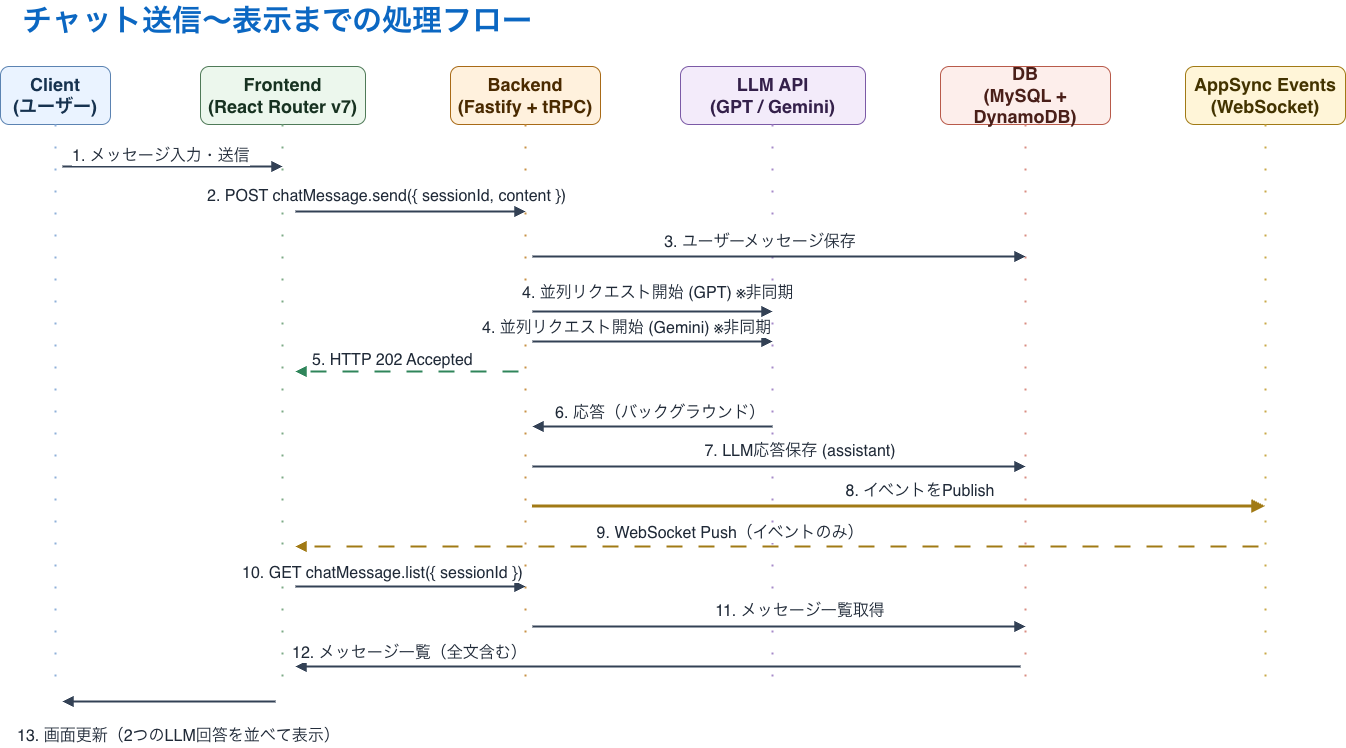
The most important design choice here was deciding what to send over the real-time channel. This time, we did not distribute message bodies through AppSync Events. We only notified clients with minimal signals such as sessionId and update events, and always fetched the actual content again through chatMessage.list. Chat content should never leak, so we wanted to minimize the exposure surface before optimizing for real-time richness. This idea was heavily inspired by the discussion of balancing real-time behavior and security in NOT A HOTEL’s plan to replace its in-app chat infrastructure, or rather, I basically copied it.
With that approach, even if the real-time delivery layer had a configuration mistake or a bug, the information that could leak would be limited to something like “something was updated.” The actual content stayed behind the same authentication and authorization boundary as the normal API, which made the security model much simpler.
The other intention was to keep the database as the single source of truth. If the UI depends entirely on pushed events, you have to think much more carefully about consistency during reconnects or missed events. With this design, the frontend only needs to re-fetch the list when it gets a notification, and it will converge to the final state. We kept the product feeling real-time enough while also making implementation and recovery simpler.
Technology Choices
The base assumptions were TypeScript, Node.js, and a monorepo. On top of that, these were the main technologies we used.
I chose TypeScript for a very practical reason: it was basically the only language all five of us could write with confidence.
Node.js was honestly chosen a bit by vibe. If I were making the same decision now, I would probably consider Bun as well. At the time, though, we were under enough time pressure that I was nervous about getting blocked by some vague package-manager instability, even if that concern was mostly based on reputation rather than hard evidence.
We chose a monorepo because, for a small team working on a short project, it makes the codebase easier to see and reason about. Personally, I still think multi-repo setups are often easier operationally, but we did not have the margin to optimize that far ahead.
- Fastify
- tRPC
- Vercel AI SDK
- Kysely
- Zod + Standard Schema
- ECS on Fargate
- Aurora Serverless v2 / DynamoDB
- AppSync Event API
The technologies that may be less familiar are tRPC, AppSync Event API, and Standard Schema.
What Is tRPC?
tRPC is an RPC library built for full-stack TypeScript, where procedures defined on the server can be called from the client in a type-safe way. Instead of maintaining a separate API schema and generated client code like in a REST setup, the input and output types flow directly from the server definitions to the frontend. In this project, that meant backend type changes immediately surfaced as compile errors on the frontend, which significantly reduced both spec drift and API maintenance overhead.
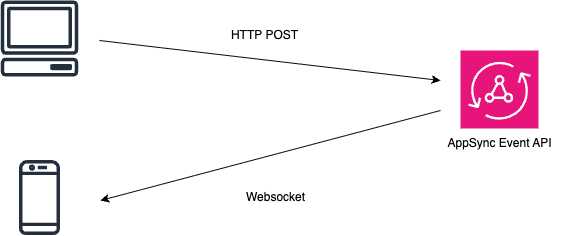
What Is AppSync Event API?
AppSync Event API is AWS’s fully managed event delivery infrastructure for Pub/Sub over WebSockets. The diagram communicates it best, but my mental model was that it is essentially the eventing part of GraphQL subscriptions extracted into its own service, without actually involving GraphQL. Clients subscribe to a channel, servers publish events to that channel, and you avoid owning too much of the connection management and scaling yourself.
In this project, it worked well because we could emit update notifications after LLM generation completed without letting the backend become responsible for long-lived WebSocket connections. That made a stateless architecture much easier. We initially considered GraphQL subscriptions, but once I realized that a modern implementation would still mean holding WebSocket connections on the server side, I wanted to avoid that structure if possible. That is when I found AppSync Event API. This was almost my first real AWS project, so there may well have been better options, but for this MVP it fit very well. As for why we used ECS/Fargate instead of Lambda, that was a separate decision: because of the time constraint, I still felt uncertain about the operational shape of running Fastify on Lambda, so we went with the more straightforward setup first.
What Is Standard Schema?
Standard Schema is a shared specification designed to let validation libraries such as Zod and Valibot be handled in roughly the same shape. It adds one layer of abstraction over the concrete validation library so that input validation and type inference boundaries can stay consistent. To be honest, one reason I picked it was that I was very influenced by an article about using ajv instead of zod, which made me think it would be better not to get too locked into a specific validation layer. The choice was made somewhat casually, but if I think in terms of working with TypeScript for a long time, I would like to believe it was not a bad call because it reduced lock-in.
I Did Not Skip Design Just Because the Project Was Short
There were three technical points I cared about most.
1. We Adopted Hexagonal Architecture
In a typical four-layer architecture, domain logic tends to get pulled around by infrastructure concerns, and changes to databases or external APIs can leak directly into business logic.
To avoid that, we centered the design on use cases and pushed MySQL, DynamoDB, and the LLM gateway outward as adapters by using Hexagonal Architecture. Aligning dependencies from the outside in makes it much easier to keep the core logic relatively stable while allowing surrounding technologies to be swapped out.
At first I did wonder whether it was overkill for a two-week internship, but in practice the short timeline was exactly why it was worth building something resilient to change. We also got to use GitHub Copilot, and to be honest, there was a real sense in which the strength of LLM tooling made this level of structure feasible within the time available.
2. We Distinguished Errors at the Type Level
If every error gets collapsed into 500 Internal Server Error, the frontend cannot tell what it should show, and the backend side cannot clearly tell what should be monitored.
So we separated expected DomainErrors from SystemErrors that developers should investigate, and we made the use case return type a Result.
That made it much easier to organize:
- Errors that are safe to show to users
- Errors that should trigger logging, monitoring, or alerts
- UI handling that changes appropriately by error code
Even in short-term development, I felt that not postponing operational clarity and debuggability pays off.
3. We Established a TDD × Agentic Coding Workflow
We split tests by responsibility.
- Structural tests: lightweight checks for dependency direction and whether tests were using the real database
- Unit tests: logic verification for use cases and utility libraries
- Integration tests: end-to-end behavior from tRPC through use cases to the database
Mocking the LLM API and AppSync Events while using a real database also worked well. It made the boundary between what was guaranteed and what was still unverified much clearer.
Personally, I felt that the more you develop together with AI, the more important it becomes to define responsibility boundaries clearly and make it explicit how far tests are expected to protect you. Agentic Coding can dramatically increase implementation speed, but if those boundaries stay vague, things become fragile very quickly.
What Went Wrong
I Dug My Own TDD Pitfall and Fell Into It
What I had not fully internalized was the obvious truth that TDD only guarantees what you actually test.
I knew that in theory, so even under time pressure I intended to at least inspect the content of the tests carefully. In practice, though, there were quite a few places where I ended up evaluating them by atmosphere rather than substance.
The clearest failure was that we were not including conversation history in the context.
For example:
- User: “What’s the weather in Tokyo?”
- AI: “It’s sunny in Tokyo.”
- User: “How about Osaka?”
- AI: “What would you like to know about Osaka?”
So multi-turn conversation simply was not working properly.
That failure drove the point home for me: TDD only guarantees the range you test. A use case can look correct in isolation and still fail against a realistic user scenario. In this case the breakage was obvious enough that we caught it without a formal QA pass, but I came away convinced that tests should be written with concrete user stories in mind as much as possible.
I Also Learned a Lot About Git Operations
Another major lesson was Git workflow.
At the time, we were opening PRs directly from feature branches into main, and sometimes code got merged into main before integration testing. As a result, we ended up with incidents like revert -> revert "revert", and before every demo we had to stop and ask, “Does the current main branch really work?”
Next time, a much better flow would be:
- Merge
featurebranches intodevelop - Run integration tests on
develop - Promote only demo-ready stable versions to
main
Short projects make you want to move fast and cut corners, but that experience convinced me that the shorter the timeline is, the more valuable it becomes to keep main permanently demoable.
Remaining Issues and What I Want to Improve
We successfully shipped an MVP in two weeks, but of course there were still open issues.
Authentication and Authorization Were Not Fully Implemented
Because our priority was getting a demo working, we could not fully build the authentication foundation and authorization boundaries needed for real operation. If this were going to continue as a product, this would be the highest-priority area to improve.
No Cache Strategy
Because we chose RPC rather than REST, it is harder to benefit from infrastructure such as CDNs by default. Introducing an explicit cache strategy would improve the user experience.
The Ongoing Cost of a shared Package
One of the most interesting design points was how we handled the shared package. Early in development, we prioritized speed and wrote zod-based schemas in shared following the Standard Schema spec, then shaped the backend around those definitions. That worked well for parallel development, because the frontend and backend could move while looking at the same contract.
However, the current setup is a TypeScript monorepo built around tRPC, so in many places it would already be enough to share the backend AppRouter types directly. By introducing a separate contract layer first, we gradually took on extra cost around importing shared, keeping schemas in sync, running conversions, and managing generated artifacts. It makes sense if you are planning for external public APIs or non-TypeScript consumers in the future, but for the current requirements it is somewhat heavy, and now feels like design debt I would like to pay back.
Long term, I think it would be cleaner to lean into tRPC Router type inference and let the frontend follow backend types directly. That would dramatically reduce the responsibility of shared and create a much nicer workflow where there is no extra import step and changes are reflected immediately.
Summary
This internship was, on one hand, a straightforward experience of building something in two weeks. But in the era of coding agents especially, it also taught me very strongly that even in short projects, not throwing away design usually ends up being faster.
- Type safety through tRPC
- Stateless real-time architecture through Pub/Sub
- Easier change management through Hexagonal Architecture
- Structured error handling
- An architecture designed to be easy to discard and reshape
These are ideas I expect to keep reusing in my personal projects as well.
Running an MVP for two weeks with five people was obviously not easy, but that is exactly why the experience forced me to think much more clearly about what to throw away and what to preserve. Across design, implementation, testing, and Git workflow, it was a very dense and valuable two weeks.