Language: 日本語
GMOインターネットグループの2週間インターンで、スケーラブルなLLM Chatbot Backendを作った
GMOインターネットグループのML/WEBコースの2週間インターンで、5人チームのMVP開発に参加し、LLM ChatbotのBackendを担当した。要件、技術選定、設計、失敗と学びを振り返る。
もう結構前のことの記事になってしまうのですが、GMOインターネットグループのML/WEBコースの2週間インターンに参加しました。
今回は天秤.AIという名前の既存のプロダクトのMVPを2週間で5人で開発するというかなり実戦寄りのテーマで、私はLLM ChatbotのBackendを担当しました。短期間の開発だと、とにかく動くものを早く出したくなります。ただ、今回やってみて強く感じたのは、短期間だからこそ「動く」より「正しく動く」を最短で取りにいく設計が重要だということです。
What is 天秤.AI
天秤.AIは、ChatGPT・Claude・Geminiなど複数の生成AIに同じプロンプトを同時に投げて、最大6つまでの回答を1画面で比較できるGMOが提供するプロダクトで、AIごとの得意不得意を見比べながら、目的に合ったモデルを選びやすくするのが特徴です。統一されたUIで複数モデルをまとめて扱えるため、情報収集、文章作成、壁打ち、プロンプト改善などを効率化しやすくするためのプロダクトです。
何を作ったか
担当したBackendの要件は次のようなものでした。
- GPT と Gemini に同時にリクエストを送り、回答を並べて比較表示する
- チャットセッションを作成、取得、削除できる
- メッセージ履歴を永続化する
- トークン使用量を計測、集計する
- LLMの回答に対して投票できる
処理フローはかなりシンプルで、ユーザーの送信を受けたらまずメッセージを保存し、その後で複数のLLMに非同期で並列リクエストを飛ばします。Backendは先に 202 Accepted を返し、LLMの応答が返ってきたら保存してイベントをPublishし、Frontend側がそれを受けて一覧を再取得する形にしました。
この構成にしたことで、Backendをステートレスに保ちつつ、リアルタイムに近い体験を作れました。
実装したAPI一覧(プロシージャ)
今回実装したプロシージャは次の通りです。
v1.health.checkBackendのヘルスチェックv1.catalog.listLlms利用可能なLLMモデル一覧を返すためのプロシージャですv1.chatSession.listユーザーが持っているチャットセッションの一覧取得ですv1.chatSession.getセッション詳細の取得です。対象セッションのメタ情報や状態を取得するために使います。v1.chatSession.create新規セッションを作成するためのプロシージャです。v1.chatSession.updateTitleセッションタイトル更新用です。v1.chatSession.deleteセッション削除用ですv1.chatMessage.listセッションに紐づくメッセージ一覧の取得です。v1.chatMessage.send今回の中核になるAPIです。GPT と Gemini に対して並列でリクエストを投げます。v1.chatMessage.voteLLMの回答に対する投票用です。いいねなど8項目の評価を保持できるようにして、モデル比較のフィードバックを集められるようにしました。
今回5人で参加したと冒頭に書きましたが、役割分担としてインフラ1, バックエンド2, フロントエンド2という感じで、進めました。今回はバックエンドのもう片方の方がDB設計をかなりやってくれたので、そこに関しては軽い紹介に留めます。また、chatMessage系のプロシージャ以外はDBを単純にいじるだけなので、chatMessage系のプロシージャに注目して書きます
DBについて(簡単に)
DBは Aurora MySQL と DynamoDB を用途で分けました。一覧や集計に向いたデータは Aurora、時系列で増えるメッセージ明細は DynamoDB です。
Aurora 側では、セッション一覧、タイトル、ユーザーの所有権、モデルごとの累積トークン数や想定コストを管理しました。投票データやその集計もこちらです。並び替えや集計、関連データをまとめて扱いたいものを RDB に寄せています。
DynamoDB 側には、ユーザーの発話と各モデルの応答本文、トークン数、コスト、応答時間のような明細を保存しました。1回の入力に対して複数モデルの応答がぶら下がる構造なので、セッション単位で時系列に取りやすい形にしています。要するに、本文は DynamoDB、一覧と集計は Aurora、という分担です。
チャット送信~表示までの処理フロー
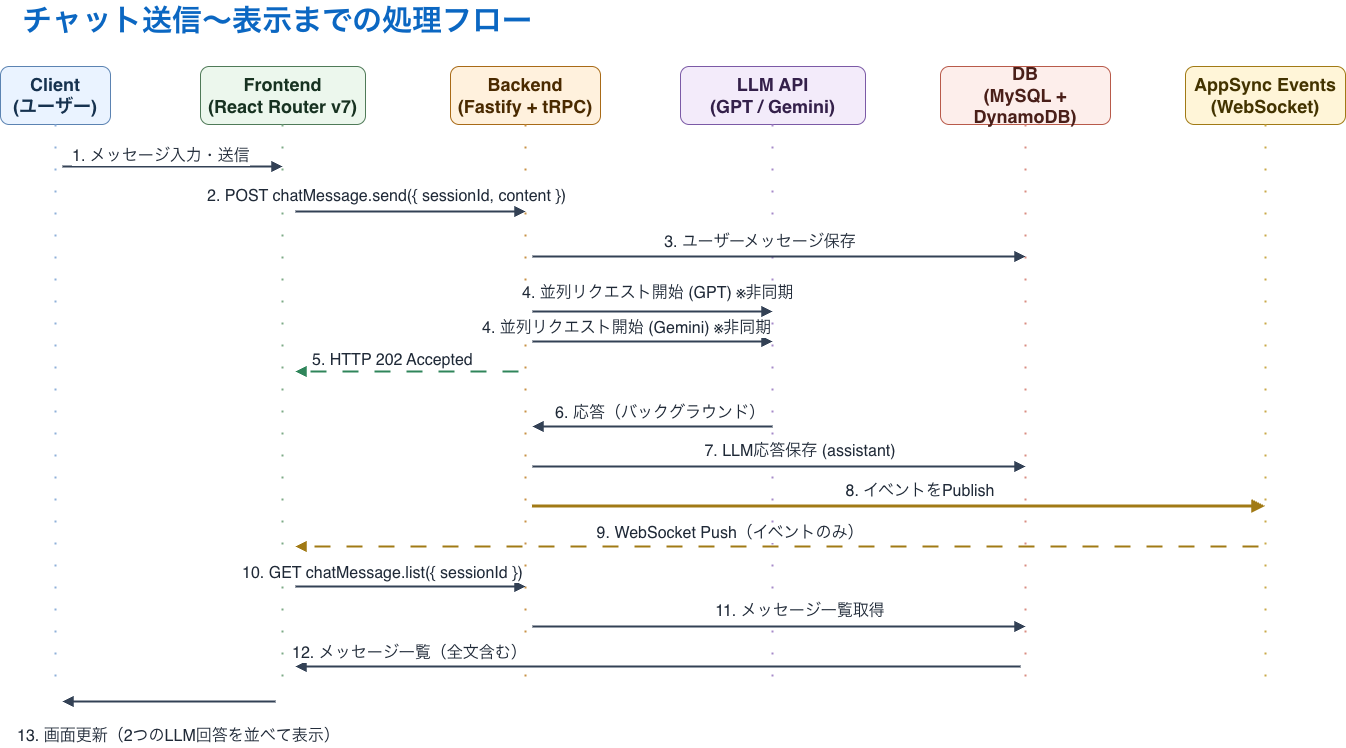
図だけだと見えにくいのですが、ここで一番意識したのは「リアルタイム通信で何を流すか」です。今回は AppSync Events で本文を配らず、sessionId や更新イベントのような最小限のシグナルだけを通知し、本文は必ず chatMessage.list で取り直す形にしました。チャット内容は漏れてはいけない情報なので、リアルタイム性よりもまず露出面を狭くしたかったからです。この考え方は、NOT A HOTELアプリのチャット基盤のリプレース計画 の「リアルタイム性とセキュリティのバランス」の話がかなり参考になりました(というよりパクりました)。
こうしておくと、万が一リアルタイム配信レイヤーに設定ミスや不具合があっても、漏れうる情報は「何か更新があった」程度に留まりやすくなります。本文取得は通常の API と同じ認証、認可の境界に寄せられるので、セキュリティ上の判断もシンプルです。
もう一つの意図は、DBを常に正本にすることです。Push だけで画面を成立させると、再接続やイベント取りこぼし時の整合性を考える必要がありますが、この構成なら Frontend は通知をきっかけに一覧を再取得するだけで最終状態に収束できます。リアルタイムっぽさは保ちつつ、実装と復旧を単純にできるのがよかったです。
技術選定
前提は TypeScript、Node.js、モノレポです。その上で、主に次の技術を使いました。 Typescriptの選択理由は、5人全員が一応かける言語がtypescriptしかなかったからです。 Node.jsは正直ノリで決めてしまったところがあり、現在ならBunも検討するべきかなと思います。ただし、正直選定当時はあまりの時間のなさの焦りから、風評でしかないのですが、パッケージマネージャーの不安定さみたいな謎ストップがかかるのが怖かったというのが正直あります。 モノレポは少人数、短期間の今回の開発からコードの見えやすさが高く適しているかという理由で選定しました。個人的には、マルチレポにした方が運用面では楽な方が多いと考えていますが、そこまで将来のことを考えた上での実装をする余裕はなかったかなと考えています。
- Fastify
- tRPC
- Vercel AI SDK
- Kysely
- Zod + Standard Schema
- ECS on Fargate
- Aurora Serverless v2 / DynamoDB
- AppSync Event API
見慣れないのは tRPC と AppSync Event API、Standard Schema だと思います。
What is tRPC
tRPC は、フルスタック TypeScript を前提に、サーバー側に定義した procedure をクライアントから型安全に呼び出せる RPC ライブラリです。REST のように別で API スキーマや client code を管理するのではなく、サーバー側の定義から入力・出力の型がそのままフロントエンドに伝わります。今回の開発では、Backend の型変更がFrontendで即コンパイルエラーになるので、仕様との齟齬や API 定義のメンテコストをかなり減らせました。
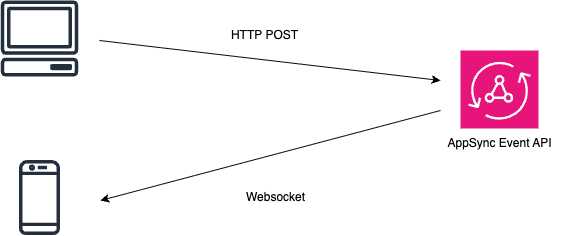
What is AppSync Event API
AppSync Event API は、AWS が提供するフルマネージドなイベント配信基盤で、WebSocket を使った Pub/Sub を扱える API です。イメージとしては図が一番わかりやすいですが、GraphQLのSubscription機能と同等の機能を切り出したサービスといった理解をしています(GraphQLは一切関係ありません)。クライアントは特定のチャンネルを subscribe し、サーバーはそのチャンネルにイベントを publish するだけでよく、接続管理やスケーリングを自前で大きく持たずに済みます。今回の開発では、LLM の生成完了や更新通知を後から流せるので、WebSocket 通信をBackendで抱え込まずに済み、ステートレスな構成にしやすかったです。当初GraphQL の Subscription を検討しましたが、どうやらモダンな実装ではWebSocketを持つ必要があるということがわかり、サーバー側で接続を持つ構成はなるべく避けたく、そのときに見つけたのが AppSync Event API でした。今回がほぼ初めての AWS だったので、もっと良いやり方はあったかもしれませんが、少なくとも今回の MVP ではかなり相性がよかったです。なお、なぜ Lambda ではなく ECS/Fargate にしたのかという話は別にあって、時間的制約により Fastify を載せたときの運用イメージにまだ不安があったので、まずは素直な構成を取りました。
What is Standard Schema
Standard Schema は、Zod や Valibot などのバリデーションライブラリを、なるべく同じ形で扱えるようにするための共通仕様です。どのライブラリを使うかという実装詳細を1段抽象化して、入力検証や型推論の境界をそろえられます。正直ここは、zod ではなく ajv を使っている話 を読んでかなり感銘を受けて、バリデーション層に強くロックインしない方がよさそうだと思って選んだ部分が大きいです。結構雑に選定したのですが、長く TypeScript と付き合う前提で考えると、結果的にはロックインを弱める判断として悪くなかったと思いたいです。
短期間開発でも設計をサボらなかった
今回、技術的に意識したポイントは大きく3つです。
1. Hexagonal Architecture を採用した
通常の4層アーキテクチャだと、ドメイン側がインフラに引っ張られやすく、DB変更や外部API変更がそのままビジネスロジックに波及しがちです。
そこで、UseCaseを中心に置いて、MySQL、DynamoDB、LLM Gateway などはAdapterとして外に逃がす Hexagonal Architecture を採用しました。依存方向を外から内に揃えることで、「コアのロジックはなるべく不変、周辺技術は差し替え可能」という状態を作りやすくなります。
2週間のインターンでここまでやるのか、という気持ちも最初はありましたが、むしろ短期間だからこそ変更に強い形にしておく価値がありました。なお今回Github Copilotを使わせてもらったのですが、LLMが強すぎてどうにかなった側面はあります。
2. 型レベルでエラーを区別した
エラーを全部 500 Internal Server Error に寄せると、Frontendは何を表示すべきか分からないし、Backend側も何を監視すべきか曖昧になります。
そこで、想定内の DomainError と、開発者が追うべき SystemError を分け、UseCaseの戻り値も Result 型にしました。
これで、
- ユーザーに見せてよいエラー
- ログ監視やアラートの対象にすべきエラー
- 画面上でエラーコードごとに適切なUIを出す処理
を整理しやすくなりました。短期開発でも、運用やデバッグのしやすさを先送りしない設計は効くと実感しました。
3. TDD × Agentic Coding の流れを作った
テストは責務ごとに分けました。
- 構造テスト: 依存の方向性の簡易チェックや、テストで実DBを使っているかのチェックなど
- 単体テスト: UseCase や lib のロジック検証
- 統合テスト: tRPC から UseCase、DB までの結合動作確認
LLM API や AppSync Events はモックして、DB は実体を使う方針にしたのもよかったです。どこまで保証されていて、どこから先は未検証なのかがかなり明確になりました。
個人的には、AIと一緒に開発するときほど、この「責務の境界を切る」「どこまでテストで固めるかを明示する」が重要だと感じました。Agentic Coding を使うと実装速度は上がりますが、境界が曖昧なままだと一気に壊れやすくなるからです。
やらかしたこと
TDDの落とし穴を自分で掘って自分でハマった
意識しきれていなかったのはTDDは「テストした範囲しか保証しない」という当たり前の事実です。 もちろんそれは考えていたので、時間がない中でもテストの中身だけはちゃんと見とこうと思っていたのですが、雰囲気だけで見てしまっていたところが結構ありました。 一番分かりやすい失敗は、会話履歴をコンテキストに入れていなかったことです。
例えば、
- ユーザー: 「東京の天気は?」
- AI: 「東京は晴れです」
- ユーザー: 「大阪は?」
- AI: 「何についてお答えすればよいですか?」
みたいな感じで、マルチターンの会話が普通に動いてませんでした。
ここで痛感したのは、TDDは「テストした範囲しか保証しない」という当たり前の事実です。ユースケース単体では正しそうでも、実際のシナリオにできるだけ準拠したテストか意識したかったです。今回は、QAなどしなくても簡単にわかる範囲で壊れていたので検出できましたが、やはり事前にストーリーを考慮したテストをかけるといいなということを学びました。
Git運用でも学びが大きかった
もう一つ大きかったのがGit運用です。
今回の進め方では feature -> main に直接PRしていて、統合テスト前に main にマージされることがありました。その結果、revert -> revert "revert" みたいな事故が起きて、デモ前に毎回「今のmainは本当に動くか?」を確認する状態になっていました。
次回以降は、
featureブランチはdevelopに集めるdevelopで統合テストを通す- デモできる安定版だけを
mainに上げる
という流れの方が明らかに良いです。
短期開発だと雑に進めたくなりますが、むしろ短期だからこそ main を常にデモ可能な状態に保つ価値が高いと感じました。
残課題と今後やりたいこと
2週間でMVPを回しきることはできましたが、もちろん残課題もあります。
認証、認可の未実装
今回はデモを成立させることを優先したので、実運用を前提にした認証基盤や認可の境界までは入れ切れていません。プロダクトとして継続的に触るなら、ここは最優先で整備すべき部分です。
キャッシュ戦略なし
今回RESTではなくRPCを採用したので、CDNなどの恩恵を受けるのが何もしない段階だと難しいです。キャッシュ戦略を入れることで、ユーザー体験を向上させることができます。
shared パッケージ運用コスト
特に面白かったのは shared パッケージの扱いでした。開発初期は実装速度を優先して、shared に zod ベースの Standard Schema 準拠スキーマを書き、Backend をそこに寄せる形で進めています。これは並行開発を素早く回すには有効で、Frontend と Backend が同じ契約を見ながら進められる安心感もありました。
ただ、現在の構成は tRPC を前提にした TypeScript モノレポなので、本来は Backend の AppRouter を型共有するだけで十分に扱える範囲も多いです。それにもかかわらず独立した契約層を先に持ち込んだことで、shared の取り込み、schema の追従、変換、生成物管理といったコストがだんだん目立つようになりました。将来の外部公開や多言語利用を見据えた設計としては意味がありますが、現状の要件に対してはやや重く、いまは返済したい設計負債になっています。
将来的には tRPC Router の型推論に寄せて、Frontend が Backend の型を直接追従する形に整理した方がきれいだと思っています。これが実現できると、shared の責務をかなり減らせて、取り込み作業不要、変更即反映、というかなり気持ちのよい状態になります。
まとめ
今回のインターンは、「2週間で作る」体験でありつつ、特にこのCoding Agent時代において「短期間でも設計を捨てない方が結局速い」ということをかなり強く学んだ時間でした。
- tRPC による型安全
- Pub/Sub を使ったステートレスなリアルタイム構成
- Hexagonal Architecture による変更容易性
- 構造化エラーハンドリング
- 捨てやすいアーキテクチャ設計
このあたりは、個人開発でも今後かなり再利用していきたい考え方です。
MVPを2週間、5人で回すのは当然楽ではなかったですが、そのぶん「何を捨てて、何を残すか」をかなり解像度高く考えられたインターンでした。設計、実装、テスト、Git運用まで含めて、かなり密度の高い2週間でした。
謝辞
今回のインターンは僕が東京に1ヶ月ほど家探しに遊びに行こうという計画で最初考えていた際にそれだけなら暇なので何かないかなという動機で申し込んだという側面があるのですが(GMOに、また大企業という場所はどんな所かという興味も元からありました)、それのせいでありえないほどタイトなスケジュールの中爆速で面接、書類対応、また年齢的な所の対応をやってくださり、結果として貴重な経験をすることができました。本当にありがとうございました!!